
«
В ходе исследования с использованием разведочного ФА можно выделить три различных этапа: 1) сбор эмпирических данных и подготовка корреляционной (ковариационной) матрицы; 2) выделение первоначальных (ортогональных) факторов; 3) вращение факторной структуры и содержательная интерпретация результатов ФА. Остановимся на них подробнее.
Второе существенное замечание возникает в связи с постулатом линейности. В случае, когда связь между психологическими характеристиками оказывается существенно нелинейной, базисная размерность искомого факторного пространства возрастает, и это приводит к ложному решению. Преодоление этой трудности может идти двумя путями. Во-первых, можно использовать коэффициент криволинейной корреляции (по Пирсону, например), а во-вторых, следует избегать тех психологических переменных, которые имеют между собой явно нелинейные связи.
На данном этапе нельзя не коснуться вопроса о необходимом уровне измерения, поскольку он в первую очередь связан с использованием конкретного метода измерения. Вычислительные алгоритмы ФА требуют, чтобы измерения наблюдаемых переменных были проведены не ниже, чем по шкале интервалов. Это требование, к сожалению, выполняется далеко не всегда, что, впрочем, свя
зано не столько с неосведомленностью исследователя, сколько с ограниченностью выбора измерительного метода и/или его адекватностью конкретной задаче или даже процедуре исследования. Реалии практики использования ФА в психологии таковы, что в подавляющем большинстве работ применяется один из вариантов метода балльной оценки, который, как известно, дает шкалу порядка. Налицо явное ограничение в использовании ФА. При решении данной Проблемы следует иметь в виду следующее. Во-первых, стоит уделить максимальное внимание проработке процедурных моментов в использовании метода балльной оценки, чтобы выйти за установление только порядковых отношений и максимально “приблизиться” к шкале интервалов. Во-вторых, следует помнить, что математическая процедура ФА оказывается достаточно устойчивой к разного рода измерительным некорректностям при оценке коэффициентов корреляции между переменными. И наконец, в самой математической статистике существуют различные подходы к решению данной проблемы (Дж. Ким, Ч. Мьюллер,1989), и для более качественной (не строго метрической) трактовки результатов ФА указанное ограничение приобретает не слишком принципиальное значение.
Достаточно важен вопрос о количестве используемых переменных или, более операционально, о том, сколько переменных должно приходиться на один гипотетический фактор. Вслед за Терстоуном многие авторы считают, что в разведочном ФА на один фактор должно приходиться не менее трех переменных. Для конфирматорного ФА эта пропорция меньше и, как правило, исследователи ограничиваются двумя переменными. Если исследователя интересует оценка надежности получаемых факторных нагрузок, существуют и более строгие оценки количества необходимых переменных (Дж. Ким, Ч. Мьюллер, 1989).
Формальный итог первого этапа — получение матрицы смешения и на ее основе — корреляционной матрицы. Матрица смешения — это таблица, куда заносятся результаты измерения наблюдаемых переменных: в столбцах матрицы (по числу переменных) представлены оцен
ки испытуемых (или одного испытуемого) каждой из переменной; строки матрицы — это различные наблюдения каждой переменной. Если задача исследователя — построить факторное пространство для одного испытуемого, то нужно обеспечить множественность таких наблюдений (например, повторить их несколько раз). В том случае, когда строится групповое факторное пространство, достаточно получить по одной оценке от каждого испытуемого. Для последующего расчета по этим данным корреляционной матрицы с достаточно достоверными коэффициентами корреляции следует обеспечить необходимое число наблюдений, т.е. количество строк в матрице смешения. Обычно ие следует планировать меиее 11 — 12 наблюдений.
Корреляционная матрица (матрица попарных корреляций между переменными) рассчитывается, как правило, с использованием коэффициента линейной корреляции Пирсона. Часто возникает вопрос о возможности и Правомерности использовать другие меры сходства (со- пряженнности) между переменными, основанные на ранговой (порядковой) статистике. Понятно, что данный вопрос возникает всегда, когда исследователь работает с номинальными или порядковыми данными. В строгом смысле ответ будет отрицательным. Однако следует принять во внимание два соображения. Во-первых, показано, что при достаточном числе наблюдений коэффициент линейной корреляции Пирсона достаточно устойчив к использованию при расчетах результатов порядковых измерений. Во-вторых, как было отмечено выше, если перед исследователем стоит задача ие столько количественного, сколько качественного анализа данных, то такое эвристическое использование ФА считается вполне оправданным.
Еще один тонкий вопрос, связанный с построением матрицы попарных корреляций связан с тем, какую матрицу использовать в ФА — корреляционную или ковариационную? Для начала напомним соответствующие формулы.
Коэффициент ковариации
Cov = -[^(xl-X)(yi-Y))
(3)
между двумя переменными х и у, а коэффициент корреляции:
(4)
где п — количество наблюдений; х и у{ — значения переменных х и у ;Х и Y — средние арифметические значения переменных х и у по ряду наблюдений; ах и ау — средние квадратические отклонения переменных х и у по ряду наблюдений.
Таким образом очевидно, что коэффициент корреляции — это тот же коэффициент ковариации, только нормированный по среднему квадратическому отклонению или, как еще говорят, выраженный в единицах среднего квадратического отклонения переменных. Из этого следуют и “рецепты” по применению в ФА корреляционной или ковариационной матриц:
И = И х И • (5)
где ||Л|| — редуцирован ная корреляционная матрица;
\F j — редуцированная матрица факторных нагрузок;
F' — транспонированная матрица факторных нагрузок.
Поясним, что редуцированная корреляционная матрица — это матрица попарных корреляций наблюдаемых переменных, где на главной диагонали лежат не единицы (как в полиой матрице корреляций), а значения, соответствующие влиянию только общих для этих переменных факторов и называемые общностями. Аналогичным образом, редуцированная матрица факторных нагрузок или факторная матрица (формальная цель ФА) представляет собой факторные нагрузки только общих факторов.
Основная проблема, стоящая при решении уравнения (3), заключается в том, что значения общностей в редуцированной корреляционной матрице неизвестны, а для начала вычислений их необходимо иметь. На первый взгляд неразрешимая проблема решается таким образом: до начала вычислений задаются некоторые приблизительные значения общностей (например, максимальный коэффициент корреляции по столбцу), а затем на последующих стадиях вычислений, когда уже имеются предварительные величины вычисленных факторных нагрузок, они уточняются. Таким образом, очевидно, что вычислительные алгоритмы ФА представляют собой последовательность итеративных[XXII] вычислений, где результаты каждого последующего шага определяются результатами предыдущих. С известной долей упрощения можно считать, что
различные алгоритмы факторизации корреляционной матрицы в основном и отличаются тем, как конкретно решается данная проблема.
Для людей, неискушенных в проблемах математической статистики, но решающих с помощью ФА свою задачу, более важен основной смысл процедуры факторизации, заключающийся в переходах от матрицы смешения к корреляционной матрице и далее к матрице факторных нагрузок и построению факторных диаграмм (рис. 2).
Матрица
смешения
Факторная
матрица
Корреляционная матрица
ги Г|,2 п,3 Г|,4 Г 1,5 Г|.Й|
Г2,і Г2.2 Гі.3 Г2.4 Г2.5 П.6І
Гз.І Г3.2 П,3 ГМ ГЗ.З Г3.6І
Г4.1 П,2 Г4.Э Г4.4 1*0 Г4.6|
Г5.1 Г5.2 Г5.3 Г5,4 Г5.5 Г5.6І
Гamp;І Тamp;Л ГМ 1*6.5 Г6.6І
Факторная даграмма
F1
F2
Рис. 2. Основные этапы трансформации данных в ходе факторного анализа
Пользуясь данным рисунком, еще раз подчеркнем важную особенность ФА — это способ понижения размерности, сжатия объема данных. Обратите внимание, что исходная матрица смешения достаточно, велика, например, при условии 20-ти наблюдений каждой переменной она содержит 20 х6=120 измерений. Конечный ре-, зультат анализа — это всего лишь 2x6=12 чисел или по
строенная по матрице факторных нагрузок компактная факторная диаграмма. Таким образом, при адекватном использовании ФА как метода многомерного измерения мы можем получить 10-кратную компрессию исходной информации и наглядность результатов ее анализа.
Напомним, что главная цель выделения первичных факторов в разведочном ФА состоит в определении минимального числа общих факторов, которые удовлетворительно воспроизводят (объясняют) корреляции между наблюдаемыми переменными. Основная стратегия при выделении факторов незначительно отличается в разных методах. Она заключается в оценке гипотезы о минимальном числе общих факторов, которые оптимально воспроизводят имеющиеся корреляции. Если нет каких-либо предположений о числе факторов (в ряде программ оно может быть задано прямо), то начинают с однофакгорной модели. Эта гипотеза о достаточности одного фактора оценивается с помощью используемого критерия оптимальности соответствия данной однофакторной модели исходной корреляционной матрице. Если расхождение статистически значимо, то на следующем шаге оценивается модель с двумя факторами и т. д. Такой процесс подгонки модели под данные осуществляется до тех пор, пока с точки зрения используемого критерия соответствия расхождение не станет минимальным и будет оцениваться как случайное. В современных компьютерных статистических программах используются различные методы факторизации корреляционной матрицы. Нам представляется, что, хотя для исследователя данная проблема не представляет прямого интереса, тем не менее она важна, поскольку от выбора метода факторизации в определенной мере зависят результаты расчета факторных нагрузок. В силу специфики нашего изложения основ ФА мы ограничимся лишь перечислением этих методов, снабдив его очень краткими комментариями и отошлем читателя для более глубокого знакомства к специальной литературе, требующей некоторых познаний в математике (Дж. Ким,
Ч. Мьюллер, 1989):
Метод главных факторов (или главных осей) — наиболее старый и часто используемый в различных предметных областях.
Метод наименьших квадратов сводится к минимизации остаточной корреляции после выделения определенного числа факторов и к оценке качества соответствия вычисленных и наблюдаемых коэффициентов корреляции по критерию минимума суммы квадратов отклонений.
Метод максимального правдоподобия: специфика дан-, ного метода состоит в том, что в случае большой выборки (большого количества наблюдений каждой переменной) он позволяет получить статистический критерий значимости полученного факторного решения.
Альфа-факторный анализ был разработан специально для анализа психологических данных, и поэтому его выводы носят в основном психометрический, а не статистический характер. В альфа-факторном анализе минимальное количество общих факторов оценивается по величинам собственных значений факторов и коэффициентов обобщенности а, которые должны быть больше 1 и 0, соответственно.
Факторизация образов (или анализ образов). В отличие от классического ФА в анализе образов предполагается, что общность каждой переменной определяется не как функция гипотетических факторов, а как линейная регрессия всех остальных переменных.
В табл. 1 представлены сравнительные результаты факторизации корреляционной матрицы (Дж. Ким, Ч. Мьюл- лер, 1989, с. 10), с использованием 4-х различных методов. Видно, что полученные результаты могут различаться, даже если не обращать внимание на знаки факторных нагрузок (об этом чуть ниже).
После компьютерного расчета матрицы факторных нагрузок наступает наиболее сложный, ответственный и творческий этап использования ФА — определение минимального числа факторов, адекватно воспроизводящих наблюдаемые корреляции, и содержательная интерпретация результатов ФА. Напомним, что максимальное количество факторов равно числу переменных. Кроме
Таблица 1
Использование различных методов факторизации для получения двухфакторного решения
содержательных критериев решения вопроса о минимальном числе факторов существуют формально-статистичес- кие показатели достаточности числа выделенных факторов для объяснения корреляционной матрицы. Остановимся на двух основных показателях. После расчета факторных нагрузок для каждой переменной практически любая компьютерная программа распечатывает на экране следующую табл. 2*.
Первый важный показатель в этой таблице (второй столбец) — это величина собственного значения каждого фактора; факторы расположены в таблице по убыванию этой величины. Не очень строго говоря, этот показатель характеризует вес, значимость каждого фактора в найденном факторном решении[XXIII]. Из таблицы 2 видно, что от 1-го фактора к 10-му (всего было 10 переменных) вели-
Таблица 2
Статистические показатели для определения минимального количества факторов
чина собственного значения убывает более, чем в 100 раз. Естественно возникает вопрос о том, какая величина данного показателя свидетельствует о значимом, существенном вкладе соответствующего фактора, и каков критерий для отсечения незначимых, несущественных факторов. Достаточно часто в качестве такого критического значения используют величину собственного значения, равную 1.0. Таким образом, с определенной степенью уверенности предполагают, что те факторы, у которых этот показатель меньше 1.0, не вносят значительного вклада в объяснение корреляционной матрицы. Кроме анализа табличных величин бывает полезно визуально оценить динамику величины собственного значения по графику. Как правило, в большинстве статистических программ такая возможность пользователю предоставляется (см. рис. 3). Как предлагал в свое время Р. Кеттел (1965), выделение факторов заканчивается, когда после резкого падения величины собственного значения изменяются незначительно, и график фактически превращается в горизонтальную прямую линию. Несмотря на видимую простоту и ясность такого рецепта, следует отметить, что когда на графике имеется более чем один излом, то выделение горизонтального участка становится неоднозначным.
1 2345678 N
Рис. 3. Изменение величины собственного значения факторов:
ось абсцисс — количество факторов; ось ординат — величина собственного значения
Другой не менее важный расчетный показатель значимости каждого фактора — процент объясняемой дисперсии переменныху содержащейся в корреляционной матрице (третий столбец в табл. 2). Естественно, что все 100% дисперсии будут объясняться только всеми десятью факторами. Однако не стоит забывать, что при любых измерениях (а особенно в разведочных, пилотажных исследованиях) имеют место разного рода случайные ошибки, и поэтому их вклад в общую дисперсию тоже может оказаться весьма значительным. Предполагается, что ряд выделенных факторов отражает влияние случайных процессов, никак не связанных с оценкой наблюдаемых переменных. Таким образом, формально задача заключается в том, чтобы, с одной стороны, выбрать некоторое минимальное количество факторов, которые бы, с другой стороны, объясняли достаточно большой процент всей дисперсии переменных. Ясно, что эти два требования в принципе взаимно противоречивы, и, следовательно, исследователь стоит перед выбором некоторой критической величины процента объясняемой дисперсии. К сожалению, никаких строго формальных рецептов по этому поводу не существует, но принято считать, что при хорошем фак
торном решении выбирают столько факторов, чтобы они в сумме (последний столбец таблицы) объясняли не менее 70—75%. В хорошо спланированных исследованиях с установленной факторной структурой этот суммарный процент может достигать 85—90 %.
Подводя итог, укажем, что в данном случае оба статистических критерия вполне однозначно свидетельствуют о достаточности не более 3-х факторов, что и отмечено пунктирной горизонтальной линией. Тем не менее, стоит подчеркнуть, что главным критерием для выделения минимального количества будет содержательная интерпретация выделенных факторов, а к использованию формально-статистических критериев следует относиться с осторожностью.
F2
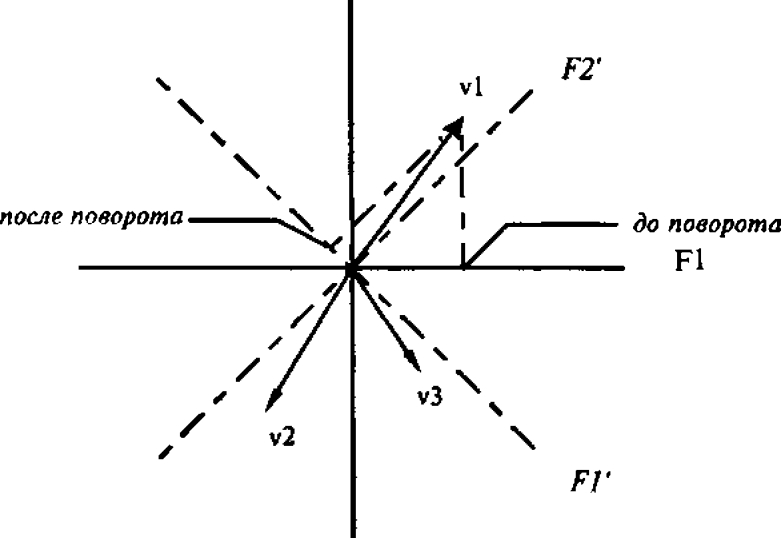
Рис.4. Факторное пространство 3-х переменных {v1, v2 и v3) в пространстве 2-х факторов: сплошные линии (F1, F2) —до поворота; пунктирные линии (F1\ F2*) — после поворота
Естественно, возникает вопрос об оптимальном расположении переменных в пространстве факторных осей. Как было отмечено выше, эта проблема в принципе не имеет строгого математического решения. Она относится уже к содержательной интерпретации расположения переменных в факторном пространстве. Фактически суть проблемы состоит в следующем: какой набор факторных нагрузок (или какая геометрическая модель результатов ФА) будет более подходящим для интерпретации иссле
дователем. Поскольку при повороте осей координат факторные наїрузки по одному фактору могут расти, а по другому — уменьшаться, то, соответственно, будет расти или уменьшаться вклад этих факторов в разные переменные. Из этого следует, что нужно искать такой вариант расположения переменных в факторном пространстве, который наилучшим образом соответствует ожиданиям исследователя, его предположениям о взаимосвязи и взаимозависимости исследуемых переменных. Как правило, при использовании ФА полагают, что существует одно оптимальное положение осей координат, соответствующее существенным для данного исследования и хорошо интерпретируемым факторам.
Описанный выше процесс поиска оптимальной факторной структуры получил название процедуры вращения факторов. По образному выражению JI. Терстоуна, цель исследователя заключается в поиске “простой структуры " или попытке объяснить большее число переменных меньшим числом факторов. С формальной точки зрения при поиске простой структуры следует иметь в виду следующее: целесообразно стремиться к получению для каждой переменной максимального числа больших факторных нагрузок по одним факторам и одновременно наибольшего количества минимальных факторных нагрузок по другим факторам. Следуя этому правилу, мы стремимся сделать так, чтобы одну группу переменных можно было в большей степени объяснить влиянием одних факторов, а другую — других. Таким образом, “простота” хорошего факторного решения заключается в том, что каждая переменная имеет наиболее простое факторное объяснение, т.е. характеризуется преобладающим влиянием некоторого одного фактора, и в меньшей степени связана с другими факторами. И наоборот: один фактор должен быть специфическим образом связан с одной группой переменных и не связан с другими переменными. В предельном случае самая простая структура получается тогда, когда все переменные располагаются на соответствующих факторных осях, т. е. имеют ненулевые факторные нагрузки только по одному фактору, а по остальным — нулевые. Возвращаясь к
рис. 4, укажем на результат вращения: после поворота факторных осей на 45 грamp;чусов вправо, нагрузка переменной vl по первому фактору резко уменьшилась и одновременно немного возросла по второму. Кроме того заметно уменьшились факторные нагрузки переменных v2 и v3 по второму фактору. Таким образом “простота” новой факторной структуры выразилась в доминирующем влиянии первого фактора на переменную vl, а второго фактора — на две других переменных.
Видимая простота решения проблемы вращения системы координат в двухмерном случае (это можно сделать и вручную) становится неочевидной при 3-х и более факторах. Пересчет системы координат вручную и построение факторных диаграмм становятся очень сложными. Исходя из общего принципа построения простой структуры, изложенного выше, во многих компьютерных программах предлагаются несколько способов решения проблемы оптимальности вращения системы координат. Кратко остановимся на основных способах вращения. Выделяют два класса методов вращения — методы ортогонального вращения, когда при повороте осей координат угол между факторами остается прямым (и, следовательно, остается верным предположение о некоррелированности факторов), и более общие методы косоугольного вращения, когда первоначальное ограничение о некоррелированности факторов снимается.
Методы ортогонального вращения: варимакс, квар- тимакс, эквимакс и биквартимакс. Варимакс — наиболее часто используемый на практике метод, цель которого — минимизировать количество переменных, имеющих высокие нагрузки на данный фактор, что способствует упрощению описания фактора за счет группировки вокруг него только тех переменных, которые с ним связаны в большей степени, чем остальные.
Квартимакс в определенном смысле противоположен варимаксу, поскольку минимизирует количество факторов, необходимых для объяснения данной переменной; поэтому он усиливает интерпретабельность переменных. Квартимакс-вращение приводит к выделению одного из общих факторов с достаточно высокими нагрузками на
большинство переменных. Эквимакс и биквартимакс — это два схожих метода, представляющих собой своеобразную комбинацию варимакса, упрощающего описание факторов, и квартимакса, упрощающего описание переменных. Отметим, что выбор более подходящего метода вращения конечно же требует известного опыта использования ФА, однако специальные исследования X. Кайзера (1958) при прочих равных условиях свидетельствуют в пользу преимущественного применения варимакса.
Методы косоугольного вращения также позволяют упростить описание факторного решения за счет введения предположения о коррелированности факторов и, следовательно, о возможности существования факторов более высокого порядка, объясняющих наблюдаемую корреляцию. Основное преимущество косоугольного вращения состоит в возможности проверки ортогональности получаемых факторов: если в результате вращения получаются действительно ортогональные факторы, то можно быть уверенным в том, что ортогональность им действительно свойственна, а не является следствием использования метода ортогонального вращения. В статистических программах наибольшую популярность получил метод облимин, по своей сути эквивалентный методу эквимакс при ортогональном вращении. В расчетах с помощью облимина используется специальный параметр (называемый в разных программах а или S), задающий степень косоугольности факторов при вращении. Большие отрицательные значения этого параметра соответствуют наиболее косоугольным решениям, а меньшие отрицательные значения — наиболее ортогональному решению. Подробнее об использовании метода облимин можно прочитать в книге Г. Хармана (1972) и руководствах к соответствующим статистическим пакетам.
Стоит особо отметить, что перед выполнением процедуры вращения следует указать количество факторов, в пространстве которых и производится вращение. Поэтому вопрос о минимальном количестве факторов следует решить (в первом приближении!) до того. После осуществления вращения и анализа факторных диаграмм мож
но еще раз вернуться к проблеме минимального количества факторов, чтобы затем еще раз выполнить вращение с другим количеством (меньшим или большим) факторов. Например, на основании использования ряда статистических критериев, описанных выше, мы начинаем проводить вращение с учетом наличия 4-х факторов, но в ходе анализа факторных диаграмм убеждаемся в избыточности третьего и четвертого факторов и окончательное вращение выполняем в 2-х факторном пространстве. Таким образом, вращение и анализ факторных диаграмм следует проводить несколько раз с учетом разного количества факторов, начиная, как правило, с избыточного количества.
Вместе с тем не следует думать, что получение простой геометрической модели факторного решения является основным критерием “хорошеети” результатов ФА
и, следовательно, единственности и оптимальности расположения исследуемых переменных в системе факторных координат. Безусловно, решение вопроса о минимальном количестве факторов и сравнительная оценка различных вариантов вращения должны основываться на серьезном содержательном анализе полученных результатов. Укажем на основные моменты в ходе содержательного анализа:
В ходе исследования с использованием разведочного ФА можно выделить три различных этапа: 1) сбор эмпирических данных и подготовка корреляционной (ковариационной) матрицы; 2) выделение первоначальных (ортогональных) факторов; 3) вращение факторной структуры и содержательная интерпретация результатов ФА. Остановимся на них подробнее.
- Сбор эмппрпческих даппых в психологическом исследовании разведочного плана всегда опосредован использованием какой-либо измерительной процедуры, в ходе которой испытуемый оценивает измеряемый объект (стимул) по ряду предложенных исследователем характе
ристик. На этом этапе очень важно, чтобы исследователем был предложен достаточно большой набор характеристик, всесторонне описывающих измеряемый объект. Подбор важны? и разнообразных характеристик и одновременно исключение лишних и несущественных — это достаточно трудное дело, требующее от исследователя опыта, знания литературы и, в известной степени, интуиции. Именно продуманный и удачный подбор оцениваемых характеристик определяет в конечном счете успех в выделении существенных и значимых факторов, стоящих за ними — это основное, о чем нельзя забывать на данном этапе. Иначе говоря, из случайного набора характеристик объекта невозможно выделить такие факторы, которые будут закономерно и содержательно определять его оценку испытуемыми. Понятно, что с первого раза, априорно бывает трудно подобрать нужные характеристики. Поэтому еще раз напомним, что разведочное исследование с помощью ФА — это длительный и интера- тивный процесс, когда результаты предыдущего анализа позволяют оценить допущенные ошибки и скорректировать процедуру последующего исследования.
Второе существенное замечание возникает в связи с постулатом линейности. В случае, когда связь между психологическими характеристиками оказывается существенно нелинейной, базисная размерность искомого факторного пространства возрастает, и это приводит к ложному решению. Преодоление этой трудности может идти двумя путями. Во-первых, можно использовать коэффициент криволинейной корреляции (по Пирсону, например), а во-вторых, следует избегать тех психологических переменных, которые имеют между собой явно нелинейные связи.
На данном этапе нельзя не коснуться вопроса о необходимом уровне измерения, поскольку он в первую очередь связан с использованием конкретного метода измерения. Вычислительные алгоритмы ФА требуют, чтобы измерения наблюдаемых переменных были проведены не ниже, чем по шкале интервалов. Это требование, к сожалению, выполняется далеко не всегда, что, впрочем, свя
зано не столько с неосведомленностью исследователя, сколько с ограниченностью выбора измерительного метода и/или его адекватностью конкретной задаче или даже процедуре исследования. Реалии практики использования ФА в психологии таковы, что в подавляющем большинстве работ применяется один из вариантов метода балльной оценки, который, как известно, дает шкалу порядка. Налицо явное ограничение в использовании ФА. При решении данной Проблемы следует иметь в виду следующее. Во-первых, стоит уделить максимальное внимание проработке процедурных моментов в использовании метода балльной оценки, чтобы выйти за установление только порядковых отношений и максимально “приблизиться” к шкале интервалов. Во-вторых, следует помнить, что математическая процедура ФА оказывается достаточно устойчивой к разного рода измерительным некорректностям при оценке коэффициентов корреляции между переменными. И наконец, в самой математической статистике существуют различные подходы к решению данной проблемы (Дж. Ким, Ч. Мьюллер,1989), и для более качественной (не строго метрической) трактовки результатов ФА указанное ограничение приобретает не слишком принципиальное значение.
Достаточно важен вопрос о количестве используемых переменных или, более операционально, о том, сколько переменных должно приходиться на один гипотетический фактор. Вслед за Терстоуном многие авторы считают, что в разведочном ФА на один фактор должно приходиться не менее трех переменных. Для конфирматорного ФА эта пропорция меньше и, как правило, исследователи ограничиваются двумя переменными. Если исследователя интересует оценка надежности получаемых факторных нагрузок, существуют и более строгие оценки количества необходимых переменных (Дж. Ким, Ч. Мьюллер, 1989).
Формальный итог первого этапа — получение матрицы смешения и на ее основе — корреляционной матрицы. Матрица смешения — это таблица, куда заносятся результаты измерения наблюдаемых переменных: в столбцах матрицы (по числу переменных) представлены оцен
ки испытуемых (или одного испытуемого) каждой из переменной; строки матрицы — это различные наблюдения каждой переменной. Если задача исследователя — построить факторное пространство для одного испытуемого, то нужно обеспечить множественность таких наблюдений (например, повторить их несколько раз). В том случае, когда строится групповое факторное пространство, достаточно получить по одной оценке от каждого испытуемого. Для последующего расчета по этим данным корреляционной матрицы с достаточно достоверными коэффициентами корреляции следует обеспечить необходимое число наблюдений, т.е. количество строк в матрице смешения. Обычно ие следует планировать меиее 11 — 12 наблюдений.
Корреляционная матрица (матрица попарных корреляций между переменными) рассчитывается, как правило, с использованием коэффициента линейной корреляции Пирсона. Часто возникает вопрос о возможности и Правомерности использовать другие меры сходства (со- пряженнности) между переменными, основанные на ранговой (порядковой) статистике. Понятно, что данный вопрос возникает всегда, когда исследователь работает с номинальными или порядковыми данными. В строгом смысле ответ будет отрицательным. Однако следует принять во внимание два соображения. Во-первых, показано, что при достаточном числе наблюдений коэффициент линейной корреляции Пирсона достаточно устойчив к использованию при расчетах результатов порядковых измерений. Во-вторых, как было отмечено выше, если перед исследователем стоит задача ие столько количественного, сколько качественного анализа данных, то такое эвристическое использование ФА считается вполне оправданным.
Еще один тонкий вопрос, связанный с построением матрицы попарных корреляций связан с тем, какую матрицу использовать в ФА — корреляционную или ковариационную? Для начала напомним соответствующие формулы.
Коэффициент ковариации
Cov = -[^(xl-X)(yi-Y))
(3)
между двумя переменными х и у, а коэффициент корреляции:
(4)
где п — количество наблюдений; х и у{ — значения переменных х и у ;Х и Y — средние арифметические значения переменных х и у по ряду наблюдений; ах и ау — средние квадратические отклонения переменных х и у по ряду наблюдений.
Таким образом очевидно, что коэффициент корреляции — это тот же коэффициент ковариации, только нормированный по среднему квадратическому отклонению или, как еще говорят, выраженный в единицах среднего квадратического отклонения переменных. Из этого следуют и “рецепты” по применению в ФА корреляционной или ковариационной матриц:
- если все переменные выражены в одних и тех же единицах измерения, то нет большого различия, какую из матриц факторизовать;
- если метрики переменных заметно отличаются (единицы измерения значительно неоднородны и дисперсии переменных заметно отличаются), то целесообразно использовать анализ корреляционной матрицы;
- ковариационные матрицы предпочтительнее, когда необходимо провести сравнение результатов ФА (факторных структур) в двух различных выборках, полученных в одном и том же исследовании, например, когда требуется оценить повторяемость какого-либо интересного результата.
- Следующий важнейший этап ФА — собственно факторизация матрицы корреляций (ковариаций) или выделение первопачалъиых (ортогональных) факторов. В настоящее время — это полностью компьютеризованная процедура, которую можно найти во всех современных статистических программах. Одним из первых, кто предложил формально-математическое решение проблемы
возможности факторизации корреляционной матрицы, был JI. Терстоун. В матричной форме его известное уравнение выглядит следующим образом (подробнее см.: Я. Окунь, 1974, с. 43—49):
И = И х И • (5)
где ||Л|| — редуцирован ная корреляционная матрица;
\F j — редуцированная матрица факторных нагрузок;
F' — транспонированная матрица факторных нагрузок.
Поясним, что редуцированная корреляционная матрица — это матрица попарных корреляций наблюдаемых переменных, где на главной диагонали лежат не единицы (как в полиой матрице корреляций), а значения, соответствующие влиянию только общих для этих переменных факторов и называемые общностями. Аналогичным образом, редуцированная матрица факторных нагрузок или факторная матрица (формальная цель ФА) представляет собой факторные нагрузки только общих факторов.
Основная проблема, стоящая при решении уравнения (3), заключается в том, что значения общностей в редуцированной корреляционной матрице неизвестны, а для начала вычислений их необходимо иметь. На первый взгляд неразрешимая проблема решается таким образом: до начала вычислений задаются некоторые приблизительные значения общностей (например, максимальный коэффициент корреляции по столбцу), а затем на последующих стадиях вычислений, когда уже имеются предварительные величины вычисленных факторных нагрузок, они уточняются. Таким образом, очевидно, что вычислительные алгоритмы ФА представляют собой последовательность итеративных[XXII] вычислений, где результаты каждого последующего шага определяются результатами предыдущих. С известной долей упрощения можно считать, что
различные алгоритмы факторизации корреляционной матрицы в основном и отличаются тем, как конкретно решается данная проблема.
Для людей, неискушенных в проблемах математической статистики, но решающих с помощью ФА свою задачу, более важен основной смысл процедуры факторизации, заключающийся в переходах от матрицы смешения к корреляционной матрице и далее к матрице факторных нагрузок и построению факторных диаграмм (рис. 2).
Матрица
смешения
| Г | V] | v2 | v3 | v4 | v5 | v61 |
| 1 | ai | bi | CL | di | Є] | f« |
| 2
» |
Э2
» |
b?
¦ |
C2
» |
dz | Є2
• |
fz » 1 |
| »
JLj |
»
Эл |
•
bn |
•
Cn |
#
do |
» 1 fj |
Факторная
матрица
Корреляционная матрица
ги Г|,2 п,3 Г|,4 Г 1,5 Г|.Й|
Г2,і Г2.2 Гі.3 Г2.4 Г2.5 П.6І
Гз.І Г3.2 П,3 ГМ ГЗ.З Г3.6І
Г4.1 П,2 Г4.Э Г4.4 1*0 Г4.6|
Г5.1 Г5.2 Г5.3 Г5,4 Г5.5 Г5.6І
Гamp;І Тamp;Л ГМ 1*6.5 Г6.6І
| |Vi | FI | F2 |
| Vl | Wj.| | W|,2 |
| Iv2 | w2,i | W2.2 |
| 1 v3 | W3J | W3.2 |
| v4 | W4,1 | W4.2 |
| v5 | W5.| | WJ.21 |
| v6 | W6.1 | W612| |
Факторная даграмма
F1
F2
Рис. 2. Основные этапы трансформации данных в ходе факторного анализа
Пользуясь данным рисунком, еще раз подчеркнем важную особенность ФА — это способ понижения размерности, сжатия объема данных. Обратите внимание, что исходная матрица смешения достаточно, велика, например, при условии 20-ти наблюдений каждой переменной она содержит 20 х6=120 измерений. Конечный ре-, зультат анализа — это всего лишь 2x6=12 чисел или по
строенная по матрице факторных нагрузок компактная факторная диаграмма. Таким образом, при адекватном использовании ФА как метода многомерного измерения мы можем получить 10-кратную компрессию исходной информации и наглядность результатов ее анализа.
Напомним, что главная цель выделения первичных факторов в разведочном ФА состоит в определении минимального числа общих факторов, которые удовлетворительно воспроизводят (объясняют) корреляции между наблюдаемыми переменными. Основная стратегия при выделении факторов незначительно отличается в разных методах. Она заключается в оценке гипотезы о минимальном числе общих факторов, которые оптимально воспроизводят имеющиеся корреляции. Если нет каких-либо предположений о числе факторов (в ряде программ оно может быть задано прямо), то начинают с однофакгорной модели. Эта гипотеза о достаточности одного фактора оценивается с помощью используемого критерия оптимальности соответствия данной однофакторной модели исходной корреляционной матрице. Если расхождение статистически значимо, то на следующем шаге оценивается модель с двумя факторами и т. д. Такой процесс подгонки модели под данные осуществляется до тех пор, пока с точки зрения используемого критерия соответствия расхождение не станет минимальным и будет оцениваться как случайное. В современных компьютерных статистических программах используются различные методы факторизации корреляционной матрицы. Нам представляется, что, хотя для исследователя данная проблема не представляет прямого интереса, тем не менее она важна, поскольку от выбора метода факторизации в определенной мере зависят результаты расчета факторных нагрузок. В силу специфики нашего изложения основ ФА мы ограничимся лишь перечислением этих методов, снабдив его очень краткими комментариями и отошлем читателя для более глубокого знакомства к специальной литературе, требующей некоторых познаний в математике (Дж. Ким,
Ч. Мьюллер, 1989):
Метод главных факторов (или главных осей) — наиболее старый и часто используемый в различных предметных областях.
Метод наименьших квадратов сводится к минимизации остаточной корреляции после выделения определенного числа факторов и к оценке качества соответствия вычисленных и наблюдаемых коэффициентов корреляции по критерию минимума суммы квадратов отклонений.
Метод максимального правдоподобия: специфика дан-, ного метода состоит в том, что в случае большой выборки (большого количества наблюдений каждой переменной) он позволяет получить статистический критерий значимости полученного факторного решения.
Альфа-факторный анализ был разработан специально для анализа психологических данных, и поэтому его выводы носят в основном психометрический, а не статистический характер. В альфа-факторном анализе минимальное количество общих факторов оценивается по величинам собственных значений факторов и коэффициентов обобщенности а, которые должны быть больше 1 и 0, соответственно.
Факторизация образов (или анализ образов). В отличие от классического ФА в анализе образов предполагается, что общность каждой переменной определяется не как функция гипотетических факторов, а как линейная регрессия всех остальных переменных.
В табл. 1 представлены сравнительные результаты факторизации корреляционной матрицы (Дж. Ким, Ч. Мьюл- лер, 1989, с. 10), с использованием 4-х различных методов. Видно, что полученные результаты могут различаться, даже если не обращать внимание на знаки факторных нагрузок (об этом чуть ниже).
После компьютерного расчета матрицы факторных нагрузок наступает наиболее сложный, ответственный и творческий этап использования ФА — определение минимального числа факторов, адекватно воспроизводящих наблюдаемые корреляции, и содержательная интерпретация результатов ФА. Напомним, что максимальное количество факторов равно числу переменных. Кроме
Таблица 1
Использование различных методов факторизации для получения двухфакторного решения
| Пере
менная |
Метод главных факторов |
Метод макс. правдоподобия |
Альфа факторный анализ |
Анализ образов |
||||
| FI | F2 | F1 | F2 | F1 | F2 | F1 | F2 | |
| vl | 0.73 | — 0.32 | 0.75 - | -0.30 | 0.70 | 0.44 | 0.58 | 0.13 |
| v2 | 0.64 | — 0.28 | 0.70 - | -0.27 | 0 59 | 0.38 | 0.54 | 0.14 |
| v3 | 0.55 | — 0.24 | 0.60 - | - 0.18 | 0,50 | 0.33 | 0.48 | 0.13 |
| v4 | 0.51 | 0.47 | 0.43 | 0.36 | 0.59 | — 0.38 | 0.37 - | -0.27 |
| v5 | 0.44 | 0.41 | 0,51 | 0.61 | 0.50 | — 0.33 | 0.39 - | -0.26 |
| v6 | 0.37 | 0.34 | 0.53 | 0.25 | 0.42 | — 0.27 | 0.29 - | — 0-24 |
содержательных критериев решения вопроса о минимальном числе факторов существуют формально-статистичес- кие показатели достаточности числа выделенных факторов для объяснения корреляционной матрицы. Остановимся на двух основных показателях. После расчета факторных нагрузок для каждой переменной практически любая компьютерная программа распечатывает на экране следующую табл. 2*.
Первый важный показатель в этой таблице (второй столбец) — это величина собственного значения каждого фактора; факторы расположены в таблице по убыванию этой величины. Не очень строго говоря, этот показатель характеризует вес, значимость каждого фактора в найденном факторном решении[XXIII]. Из таблицы 2 видно, что от 1-го фактора к 10-му (всего было 10 переменных) вели-
Таблица 2
Статистические показатели для определения минимального количества факторов
| Фактор | Собственное | % | Сумм. % |
| значение | объясняемой | объясняемой | |
| дисперсии | дисперсии | ||
| 1 | 5,14 | 51.4 | 51.4 |
| 2 | 1.72 | 17.2 | 68.6 |
| 3 | 1.03 | 10.3 | 78.9 |
| 4 | 0.76 | 7.7 | 86.6 |
| 5 | 038 | 3.9 | 90.5 |
| 6 | 0.33 | 3.3 | 93.7 |
| 7 | 0.28 | 2.8 | 96.6 |
| 8 | 0.21 | 2.1 | 98.7 |
| 9 | 0.08 | 0.8 | 99.5 |
| 10 | 0.05 | 0.5 | 100 |
чина собственного значения убывает более, чем в 100 раз. Естественно возникает вопрос о том, какая величина данного показателя свидетельствует о значимом, существенном вкладе соответствующего фактора, и каков критерий для отсечения незначимых, несущественных факторов. Достаточно часто в качестве такого критического значения используют величину собственного значения, равную 1.0. Таким образом, с определенной степенью уверенности предполагают, что те факторы, у которых этот показатель меньше 1.0, не вносят значительного вклада в объяснение корреляционной матрицы. Кроме анализа табличных величин бывает полезно визуально оценить динамику величины собственного значения по графику. Как правило, в большинстве статистических программ такая возможность пользователю предоставляется (см. рис. 3). Как предлагал в свое время Р. Кеттел (1965), выделение факторов заканчивается, когда после резкого падения величины собственного значения изменяются незначительно, и график фактически превращается в горизонтальную прямую линию. Несмотря на видимую простоту и ясность такого рецепта, следует отметить, что когда на графике имеется более чем один излом, то выделение горизонтального участка становится неоднозначным.
1 2345678 N
Рис. 3. Изменение величины собственного значения факторов:
ось абсцисс — количество факторов; ось ординат — величина собственного значения
Другой не менее важный расчетный показатель значимости каждого фактора — процент объясняемой дисперсии переменныху содержащейся в корреляционной матрице (третий столбец в табл. 2). Естественно, что все 100% дисперсии будут объясняться только всеми десятью факторами. Однако не стоит забывать, что при любых измерениях (а особенно в разведочных, пилотажных исследованиях) имеют место разного рода случайные ошибки, и поэтому их вклад в общую дисперсию тоже может оказаться весьма значительным. Предполагается, что ряд выделенных факторов отражает влияние случайных процессов, никак не связанных с оценкой наблюдаемых переменных. Таким образом, формально задача заключается в том, чтобы, с одной стороны, выбрать некоторое минимальное количество факторов, которые бы, с другой стороны, объясняли достаточно большой процент всей дисперсии переменных. Ясно, что эти два требования в принципе взаимно противоречивы, и, следовательно, исследователь стоит перед выбором некоторой критической величины процента объясняемой дисперсии. К сожалению, никаких строго формальных рецептов по этому поводу не существует, но принято считать, что при хорошем фак
торном решении выбирают столько факторов, чтобы они в сумме (последний столбец таблицы) объясняли не менее 70—75%. В хорошо спланированных исследованиях с установленной факторной структурой этот суммарный процент может достигать 85—90 %.
Подводя итог, укажем, что в данном случае оба статистических критерия вполне однозначно свидетельствуют о достаточности не более 3-х факторов, что и отмечено пунктирной горизонтальной линией. Тем не менее, стоит подчеркнуть, что главным критерием для выделения минимального количества будет содержательная интерпретация выделенных факторов, а к использованию формально-статистических критериев следует относиться с осторожностью.
- Вращение факторной структуры и содержательиая интерпретация результатов ФА. Одним из основных кажущихся парадоксов ФА как метода, обеспеченного весьма солидным и современным математическим аппаратом, является неоднозначность расчета факторных нагрузок по исходной корреляционной матрице. Фактически это означает следующее: любой алгоритм факторизации корреляционной матрицы дает какой-то один вариант расчета факторных нагрузок из целого множества эквивалентных. Это'означает, что расчет факторных нагрузок выполняется с точностью до любого линейного преобразования в правой части уравнения (2), что эквивалентно возможности произвольного поворота факторных осей вокруг векторов-переменных. Поясним сказанное, используя геометрическую интерпретацию результатов ФА. На рис. 4 представлены три переменные (vl, v2 и v3) в пространстве двух ортогональных факторов (F1 и F2). Переменные изображены в виде векторов, а факторные нагрузки переменных на факторы геометрически представляют собой проекции данного вектора (переменной) на соответствующую координатную ось (фактор). Если мы осуществим произвольный поворот осей координат на какой-то угол, например, на 45 градусов вправо (новые оси — штрих-пунктирные линии на рис. 4), то расположение переменных в новой системе координат (F1' — F2)
с математической точки зреиия полностью эквивалентно исходному. Изменились лишь величины факторных нагрузок (сравните проекции переменной vl на оси F1 и F1', соответственно, до и после поворота). Таким образом, исходное факторное решение справедливо с точностью до любого угла поворота ортогональных факторных осей вокруг пучка векторов, образованного переменными vl, v2 и v3.
F2
Рис.4. Факторное пространство 3-х переменных {v1, v2 и v3) в пространстве 2-х факторов: сплошные линии (F1, F2) —до поворота; пунктирные линии (F1\ F2*) — после поворота
Естественно, возникает вопрос об оптимальном расположении переменных в пространстве факторных осей. Как было отмечено выше, эта проблема в принципе не имеет строгого математического решения. Она относится уже к содержательной интерпретации расположения переменных в факторном пространстве. Фактически суть проблемы состоит в следующем: какой набор факторных нагрузок (или какая геометрическая модель результатов ФА) будет более подходящим для интерпретации иссле
дователем. Поскольку при повороте осей координат факторные наїрузки по одному фактору могут расти, а по другому — уменьшаться, то, соответственно, будет расти или уменьшаться вклад этих факторов в разные переменные. Из этого следует, что нужно искать такой вариант расположения переменных в факторном пространстве, который наилучшим образом соответствует ожиданиям исследователя, его предположениям о взаимосвязи и взаимозависимости исследуемых переменных. Как правило, при использовании ФА полагают, что существует одно оптимальное положение осей координат, соответствующее существенным для данного исследования и хорошо интерпретируемым факторам.
Описанный выше процесс поиска оптимальной факторной структуры получил название процедуры вращения факторов. По образному выражению JI. Терстоуна, цель исследователя заключается в поиске “простой структуры " или попытке объяснить большее число переменных меньшим числом факторов. С формальной точки зрения при поиске простой структуры следует иметь в виду следующее: целесообразно стремиться к получению для каждой переменной максимального числа больших факторных нагрузок по одним факторам и одновременно наибольшего количества минимальных факторных нагрузок по другим факторам. Следуя этому правилу, мы стремимся сделать так, чтобы одну группу переменных можно было в большей степени объяснить влиянием одних факторов, а другую — других. Таким образом, “простота” хорошего факторного решения заключается в том, что каждая переменная имеет наиболее простое факторное объяснение, т.е. характеризуется преобладающим влиянием некоторого одного фактора, и в меньшей степени связана с другими факторами. И наоборот: один фактор должен быть специфическим образом связан с одной группой переменных и не связан с другими переменными. В предельном случае самая простая структура получается тогда, когда все переменные располагаются на соответствующих факторных осях, т. е. имеют ненулевые факторные нагрузки только по одному фактору, а по остальным — нулевые. Возвращаясь к
рис. 4, укажем на результат вращения: после поворота факторных осей на 45 грamp;чусов вправо, нагрузка переменной vl по первому фактору резко уменьшилась и одновременно немного возросла по второму. Кроме того заметно уменьшились факторные нагрузки переменных v2 и v3 по второму фактору. Таким образом “простота” новой факторной структуры выразилась в доминирующем влиянии первого фактора на переменную vl, а второго фактора — на две других переменных.
Видимая простота решения проблемы вращения системы координат в двухмерном случае (это можно сделать и вручную) становится неочевидной при 3-х и более факторах. Пересчет системы координат вручную и построение факторных диаграмм становятся очень сложными. Исходя из общего принципа построения простой структуры, изложенного выше, во многих компьютерных программах предлагаются несколько способов решения проблемы оптимальности вращения системы координат. Кратко остановимся на основных способах вращения. Выделяют два класса методов вращения — методы ортогонального вращения, когда при повороте осей координат угол между факторами остается прямым (и, следовательно, остается верным предположение о некоррелированности факторов), и более общие методы косоугольного вращения, когда первоначальное ограничение о некоррелированности факторов снимается.
Методы ортогонального вращения: варимакс, квар- тимакс, эквимакс и биквартимакс. Варимакс — наиболее часто используемый на практике метод, цель которого — минимизировать количество переменных, имеющих высокие нагрузки на данный фактор, что способствует упрощению описания фактора за счет группировки вокруг него только тех переменных, которые с ним связаны в большей степени, чем остальные.
Квартимакс в определенном смысле противоположен варимаксу, поскольку минимизирует количество факторов, необходимых для объяснения данной переменной; поэтому он усиливает интерпретабельность переменных. Квартимакс-вращение приводит к выделению одного из общих факторов с достаточно высокими нагрузками на
большинство переменных. Эквимакс и биквартимакс — это два схожих метода, представляющих собой своеобразную комбинацию варимакса, упрощающего описание факторов, и квартимакса, упрощающего описание переменных. Отметим, что выбор более подходящего метода вращения конечно же требует известного опыта использования ФА, однако специальные исследования X. Кайзера (1958) при прочих равных условиях свидетельствуют в пользу преимущественного применения варимакса.
Методы косоугольного вращения также позволяют упростить описание факторного решения за счет введения предположения о коррелированности факторов и, следовательно, о возможности существования факторов более высокого порядка, объясняющих наблюдаемую корреляцию. Основное преимущество косоугольного вращения состоит в возможности проверки ортогональности получаемых факторов: если в результате вращения получаются действительно ортогональные факторы, то можно быть уверенным в том, что ортогональность им действительно свойственна, а не является следствием использования метода ортогонального вращения. В статистических программах наибольшую популярность получил метод облимин, по своей сути эквивалентный методу эквимакс при ортогональном вращении. В расчетах с помощью облимина используется специальный параметр (называемый в разных программах а или S), задающий степень косоугольности факторов при вращении. Большие отрицательные значения этого параметра соответствуют наиболее косоугольным решениям, а меньшие отрицательные значения — наиболее ортогональному решению. Подробнее об использовании метода облимин можно прочитать в книге Г. Хармана (1972) и руководствах к соответствующим статистическим пакетам.
Стоит особо отметить, что перед выполнением процедуры вращения следует указать количество факторов, в пространстве которых и производится вращение. Поэтому вопрос о минимальном количестве факторов следует решить (в первом приближении!) до того. После осуществления вращения и анализа факторных диаграмм мож
но еще раз вернуться к проблеме минимального количества факторов, чтобы затем еще раз выполнить вращение с другим количеством (меньшим или большим) факторов. Например, на основании использования ряда статистических критериев, описанных выше, мы начинаем проводить вращение с учетом наличия 4-х факторов, но в ходе анализа факторных диаграмм убеждаемся в избыточности третьего и четвертого факторов и окончательное вращение выполняем в 2-х факторном пространстве. Таким образом, вращение и анализ факторных диаграмм следует проводить несколько раз с учетом разного количества факторов, начиная, как правило, с избыточного количества.
Вместе с тем не следует думать, что получение простой геометрической модели факторного решения является основным критерием “хорошеети” результатов ФА
и, следовательно, единственности и оптимальности расположения исследуемых переменных в системе факторных координат. Безусловно, решение вопроса о минимальном количестве факторов и сравнительная оценка различных вариантов вращения должны основываться на серьезном содержательном анализе полученных результатов. Укажем на основные моменты в ходе содержательного анализа:
- По возможности следует четко сформулировать ожидаемые результаты и после этого задать себе следующие вопросы: а) согласуются ли ваши данные с вашими ожиданиями и результатами ранее выполненных исследований? б) что общего и какие есть различия между вашим и другими подобными исследованиями?
- Стоит вспомнить, использовался ли ФА в сходных исследованиях и какие факторы выделялись в таких работах.
- И наконец, при интерпретации факторов и объяснении их влияния на исследуемые переменные, следует подумать о согласованности найденного вами факторного решения с теоретическими основаниями данной предметной области психологии.