
После установления химического строения и пространственной структуры ДНК оставалось еще множество вопросов, основной из которых заключался в том, как же ДНК кодирует белки, то есть, что представляет из себя генетический код этой молекулы, какую «грамматику» она использует? На это в первую очередь и были направлены дальнейшие усилия исследователей.
Итак, установлено, что «буквами» в ДНКовом тексте служат нук–леотиды – элементарные звенья полимерной молекулы ДНК. В ДНК всего 4 нуклеотида (А, Т, Г, Ц). Следовательно, если сравнить каждый из этих нуклеотидов с отдельной буквой, то алфавит ДНКового текста содержит всего 4 «буквы». Как же из этих «букв» формируются «слова» и «предложения»?
Белковые молекулы всех существующих на земле организмов построены всего из 20 аминокислот. Сразу после создания модели ДНК стало ясно, что существует некий код, переводящий четырехбуквенный ДНКовый текст в двадцатибуквенный аминокислотный текст. Элементарные расчеты говорили о том, что число возможных сочетаний, в которых четыре нуклеотида могут быть по–разному расположены в «тексте», достигает астрономических значений. Так, молекула ДНК, состоящая, к примеру, всего из 100 пар нуклеотидов, может теоретически кодировать 4100 различных белковых «текстов». Какова же ситуация на самом деле?
Одним из первых в этом пытался разобраться русский физик Г. Гамов, эмигрировавший в то время в Америку. Наслушавшись многочисленных разговоров о ДНК и узнав, что она содержит – как и карты – всего четыре «масти», Гамов решил «разложить пасьянс» с целью понять устройство генетического кода. Ему сразу стало ясно, что код не может быть «двоичным», то есть одну аминокислоту в белке должна кодировать не двойка нуклеотидов – «букв», а как минимум тройка. Дело в том, что сочетание из 4 по 2 дает всего 16 комбинаций, а этого недостаточно для кодирования всех 20 аминокислот. Следовательно, рассуждал Гамов, код должен быть по крайней мере трехбуквенным, то есть каждую аминокислоту должна кодировать тройка «букв» в любых сочетаниях. На этом он и остановился, поскольку далее возникало множество вопросов. В частности, такой: число сочетаний из 4 по 3 равно 64, а аминокислот всего 20. Зачем же такая избыточность в трехбуквенном коде?
В то время уже существовал хорошо известный путь, который, в частности, был проделан в свое время французом Жаном Шамполь–оном при дешифровке иероглифов древнего Египта. В качестве основного подспорья для решения стоящей перед ним задачи он использовал базальтовую плиту, которую обнаружили во время военной компании Наполеона в Египет и которая получила название Розеттский камень. На плите одновременно присутствовали две надписи: одна была иероглифическая, а другая – сделанная греческими буквами на греческом языке. К счастью, и язык, и письмо древних греков были в то время уже хорошо известны ученым. В результате сравнение двух текстов Розеттского камня привело к расшифровке египетской иероглифики. Этим путем и двинулись ученые при расшифровке генетического кода. Надо было сравнить два текста: текст, записанный в ДНК, с текстом, записанным в белке. Однако первоначально ученые не умели «читать» ДНК, а одного известного в то время белкового текста было недостаточно. Пришлось искусственно синтезировать разнообразные короткие фрагменты РНК и синтезировать на них в искусственных системах фрагменты белка. Весной 1961 года в Москве на Международном биохимическом конгрессе М. Ниренберг сообщил, что ему удалось «прочесть» первое «слово» в ДНКовом тексте. Это была тройка букв—ААА (в РНК, соответственно, УУУ), то есть три аденина, стоящие друг за другом,– которая кодирует аминокислоту фенилаланин в белке. Так было положено начало расшифровке генетического кода.
Такой путь в конечном итоге вскоре привел к полной расшифровке генетического кода. Подтвердилось предположение Гамова, что код триплетный: одной аминокислоте в белках соответствует последовательность из 3 нуклеотидов в ДНК и РНК. Такие кодирующие тройки нуклеотидов – «слова» – получили название кодонов.
Напомним, что еще Гамов столкнулся с парадоксом: из четырех нуклеотидов может быть построено 64 разных кодонов, а для построения белков используется только 20 различных аминокислот. Решение этого парадокса оказалось в следующем. Большинство аминокислот может кодироваться несколькими кодонами. После выяснения этого обстоятельства генетический код назвали вырожденным.
В таблице 1 приведены кодоны, но не в самой ДНК, а в РНК–посреднике (матричной РНК, или мРНК), образующейся на ДНК, и соответствующие им аминокислоты в белках.
Кроме того, как видно из таблицы, реально для кодирования используются не все возможные кодоны. Три из этих «лишних» кодонов выполняют функцию стоп–сигналов, обеспечивая прекращение синтеза белковой цепи.
Если внимательно посмотреть на таблицу 1, то видно, что вырожденность генетического кода носит не совсем случайный характер. Хотя код триплетный, основную нагрузку несут первые два нуклео–тида в каждом кодоне. Чаще всего в разных кодонах, кодирующих одну и ту же аминокислоту, отличается лишь третий нуклеотид.
Таблица 1. Генетический словарь. Указаны аминокислоты, встречающиеся в белках, и соответствующие им кодоны в комплементарной ДНК матричной РНК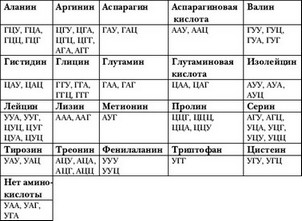
Генетический код первоначально был расшифрован у таких простых организмов, как фаги и бактерии. В дальнейшем оказалось, что он универсален (за очень редким исключением) для геномов всех существующих ныне живых организмах (от бактерий до человека). Небольшие отличия, о которых мы поговорим далее, были выявлены при сравнении ядерного и митохондриального геномов.
Итак, как в привычном нам тексте книги, вся информация записана в ДНК последовательностью расположения четырех составляющих ее «букв» – нуклеотидов. Таким образом, ДНКовый текст написан с помощью А, Т, Ц, Г–алфавита. При этом только текст одной из двух цепей ДНК обычно кодирующий, а другая цепь, как правило, некодирующая. Хотя известно, что в каждом правиле есть исключения. Если читатель попробует написать этими четырьмя буквами какие–нибудь русские слова, то у него ничего не получится. «Словом» в ДНКовом тексте, условно говоря, служит определенное сочетание трех нуклеотидов, которому соответствует конкретная аминокислота в белке, являющемся также полимером. Таким образом, в клетке четырьмя буквами записано два десятка «слов» (аминокислот – составных частей белков). И, наконец, как «предложение» в ДНКовом тексте можно рассматривать полный набор триплетов, кодирующих определенный белок, то есть ген. Таким образом, генетический алфавит состоит всего из 4 букв, а генетический словарь из 20 слов. В этой связи вспомним, что даже словарь Эллочки–людоедки из романа И. Ильфа и Е. Петрова «Двенадцать стульев» состоял из 30 слов, а «Словарь языка произведений А. С. Пушкина» насчитывает примерно 20 тыс. слов.
Существует строгая закономерность: чем длиннее код (чем больше в нем знаков), тем короче тексты. Огромный по размерам код представляют собой, например, китайские иероглифы. В результате этого иероглифические тексты существенно более кратки по сравнению с другими системами письма, в том числе и нашей. Однако для создания генетического кода природа выбрала всего 4 «буквы». Такой код предполагает наличие длинных текстов, что и реализовалось природой в виде создания гигантских молекул ДНК. При написании полного «текста» генома человека потребовалось около 3,2 млрд. «букв». Для сравнения: в священной книге Бытия, написанной на древнееврейском языке, содержится всего 78100 букв.
Итак, установлено, что «буквами» в ДНКовом тексте служат нук–леотиды – элементарные звенья полимерной молекулы ДНК. В ДНК всего 4 нуклеотида (А, Т, Г, Ц). Следовательно, если сравнить каждый из этих нуклеотидов с отдельной буквой, то алфавит ДНКового текста содержит всего 4 «буквы». Как же из этих «букв» формируются «слова» и «предложения»?
Белковые молекулы всех существующих на земле организмов построены всего из 20 аминокислот. Сразу после создания модели ДНК стало ясно, что существует некий код, переводящий четырехбуквенный ДНКовый текст в двадцатибуквенный аминокислотный текст. Элементарные расчеты говорили о том, что число возможных сочетаний, в которых четыре нуклеотида могут быть по–разному расположены в «тексте», достигает астрономических значений. Так, молекула ДНК, состоящая, к примеру, всего из 100 пар нуклеотидов, может теоретически кодировать 4100 различных белковых «текстов». Какова же ситуация на самом деле?
Одним из первых в этом пытался разобраться русский физик Г. Гамов, эмигрировавший в то время в Америку. Наслушавшись многочисленных разговоров о ДНК и узнав, что она содержит – как и карты – всего четыре «масти», Гамов решил «разложить пасьянс» с целью понять устройство генетического кода. Ему сразу стало ясно, что код не может быть «двоичным», то есть одну аминокислоту в белке должна кодировать не двойка нуклеотидов – «букв», а как минимум тройка. Дело в том, что сочетание из 4 по 2 дает всего 16 комбинаций, а этого недостаточно для кодирования всех 20 аминокислот. Следовательно, рассуждал Гамов, код должен быть по крайней мере трехбуквенным, то есть каждую аминокислоту должна кодировать тройка «букв» в любых сочетаниях. На этом он и остановился, поскольку далее возникало множество вопросов. В частности, такой: число сочетаний из 4 по 3 равно 64, а аминокислот всего 20. Зачем же такая избыточность в трехбуквенном коде?
В то время уже существовал хорошо известный путь, который, в частности, был проделан в свое время французом Жаном Шамполь–оном при дешифровке иероглифов древнего Египта. В качестве основного подспорья для решения стоящей перед ним задачи он использовал базальтовую плиту, которую обнаружили во время военной компании Наполеона в Египет и которая получила название Розеттский камень. На плите одновременно присутствовали две надписи: одна была иероглифическая, а другая – сделанная греческими буквами на греческом языке. К счастью, и язык, и письмо древних греков были в то время уже хорошо известны ученым. В результате сравнение двух текстов Розеттского камня привело к расшифровке египетской иероглифики. Этим путем и двинулись ученые при расшифровке генетического кода. Надо было сравнить два текста: текст, записанный в ДНК, с текстом, записанным в белке. Однако первоначально ученые не умели «читать» ДНК, а одного известного в то время белкового текста было недостаточно. Пришлось искусственно синтезировать разнообразные короткие фрагменты РНК и синтезировать на них в искусственных системах фрагменты белка. Весной 1961 года в Москве на Международном биохимическом конгрессе М. Ниренберг сообщил, что ему удалось «прочесть» первое «слово» в ДНКовом тексте. Это была тройка букв—ААА (в РНК, соответственно, УУУ), то есть три аденина, стоящие друг за другом,– которая кодирует аминокислоту фенилаланин в белке. Так было положено начало расшифровке генетического кода.
Такой путь в конечном итоге вскоре привел к полной расшифровке генетического кода. Подтвердилось предположение Гамова, что код триплетный: одной аминокислоте в белках соответствует последовательность из 3 нуклеотидов в ДНК и РНК. Такие кодирующие тройки нуклеотидов – «слова» – получили название кодонов.
Напомним, что еще Гамов столкнулся с парадоксом: из четырех нуклеотидов может быть построено 64 разных кодонов, а для построения белков используется только 20 различных аминокислот. Решение этого парадокса оказалось в следующем. Большинство аминокислот может кодироваться несколькими кодонами. После выяснения этого обстоятельства генетический код назвали вырожденным.
В таблице 1 приведены кодоны, но не в самой ДНК, а в РНК–посреднике (матричной РНК, или мРНК), образующейся на ДНК, и соответствующие им аминокислоты в белках.
Кроме того, как видно из таблицы, реально для кодирования используются не все возможные кодоны. Три из этих «лишних» кодонов выполняют функцию стоп–сигналов, обеспечивая прекращение синтеза белковой цепи.
Если внимательно посмотреть на таблицу 1, то видно, что вырожденность генетического кода носит не совсем случайный характер. Хотя код триплетный, основную нагрузку несут первые два нуклео–тида в каждом кодоне. Чаще всего в разных кодонах, кодирующих одну и ту же аминокислоту, отличается лишь третий нуклеотид.
Таблица 1. Генетический словарь. Указаны аминокислоты, встречающиеся в белках, и соответствующие им кодоны в комплементарной ДНК матричной РНК
Генетический код первоначально был расшифрован у таких простых организмов, как фаги и бактерии. В дальнейшем оказалось, что он универсален (за очень редким исключением) для геномов всех существующих ныне живых организмах (от бактерий до человека). Небольшие отличия, о которых мы поговорим далее, были выявлены при сравнении ядерного и митохондриального геномов.
Итак, как в привычном нам тексте книги, вся информация записана в ДНК последовательностью расположения четырех составляющих ее «букв» – нуклеотидов. Таким образом, ДНКовый текст написан с помощью А, Т, Ц, Г–алфавита. При этом только текст одной из двух цепей ДНК обычно кодирующий, а другая цепь, как правило, некодирующая. Хотя известно, что в каждом правиле есть исключения. Если читатель попробует написать этими четырьмя буквами какие–нибудь русские слова, то у него ничего не получится. «Словом» в ДНКовом тексте, условно говоря, служит определенное сочетание трех нуклеотидов, которому соответствует конкретная аминокислота в белке, являющемся также полимером. Таким образом, в клетке четырьмя буквами записано два десятка «слов» (аминокислот – составных частей белков). И, наконец, как «предложение» в ДНКовом тексте можно рассматривать полный набор триплетов, кодирующих определенный белок, то есть ген. Таким образом, генетический алфавит состоит всего из 4 букв, а генетический словарь из 20 слов. В этой связи вспомним, что даже словарь Эллочки–людоедки из романа И. Ильфа и Е. Петрова «Двенадцать стульев» состоял из 30 слов, а «Словарь языка произведений А. С. Пушкина» насчитывает примерно 20 тыс. слов.
Существует строгая закономерность: чем длиннее код (чем больше в нем знаков), тем короче тексты. Огромный по размерам код представляют собой, например, китайские иероглифы. В результате этого иероглифические тексты существенно более кратки по сравнению с другими системами письма, в том числе и нашей. Однако для создания генетического кода природа выбрала всего 4 «буквы». Такой код предполагает наличие длинных текстов, что и реализовалось природой в виде создания гигантских молекул ДНК. При написании полного «текста» генома человека потребовалось около 3,2 млрд. «букв». Для сравнения: в священной книге Бытия, написанной на древнееврейском языке, содержится всего 78100 букв.